AI is a very special (testing) problem
Why do we test? We test because there's a risk of problems about the product — not just IN the product, but also things around it and related to it. Product risk is the possibility that some person, a victim, will experience a problem due to a vulnerability in the product that is triggered by some threat — a set of circumstances that allow the problem to become manifest.
We have two things going on at the same time:
- Builders' mindset praise and its focus on fast shipping (==speeded coding). As a result, proper testing might be easily deprioritized in the backlog each time during planning (unless it’s a hot issue).
- AI-driven features are being added to existing products, and new products with LLMs (often through API, but still) as a backbone are popping up on a daily basis; while debugging ML models is a challenge by itself.
And by the burden of proof, let me justify why it is actually a problem.
Why is debugging and evaluation of ML a challenge from the ML engineer’s perspective?
- ML models fail in silence.
- As an ML system incorporates data, labels, algorithms, features, code, and infrastructure, debugging becomes a complex cross-functional issue. The problem might lie in one component or in a combination of several.
- If you think you’ve found a bug, it's not easy-peasy to validate your findings. Sometimes you need to re-train the model and re-evaluate. Sometimes you need to deploy a fix and wait for feedback from users.
And what do professional testers think?
I got very lucky to take part in a two peer conferences focused on testing AI and AI in testing. We shared experience reports, and Michael Bolton and James Bach presented analysis of how testing AI is different than testing other kinds of software.
Algorithmic obscurity, radical fragility, wishful claims, social intrusiveness, and corporate defensiveness are not topics often thought about or dealt with by AI engineering teams.
And we do need fellow thinkers to widen the context and add layers here.
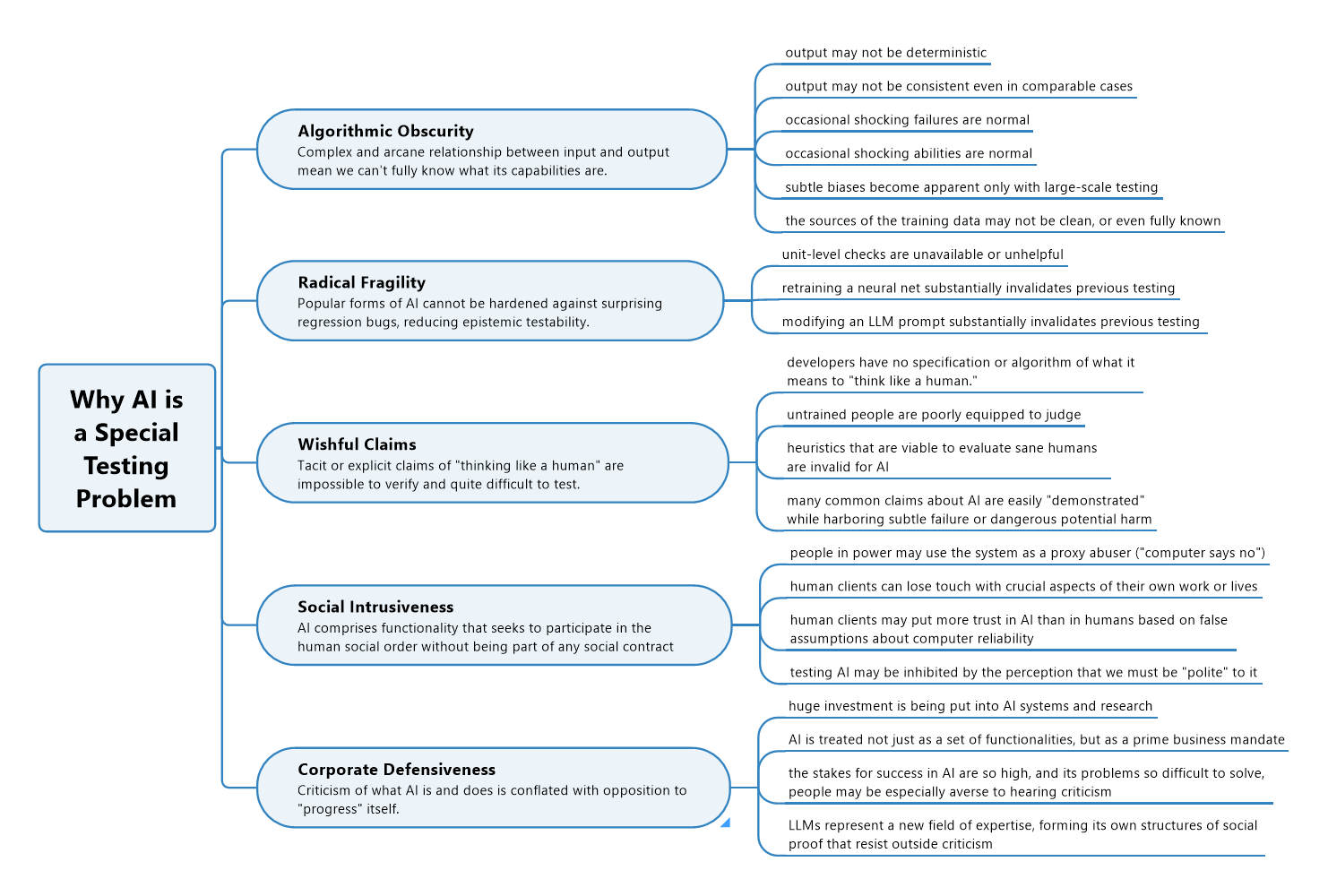
From a business perspective, there is a push to ship “good enough” products. From AI development, there are numerous evaluation and monitoring frameworks. But here’s the thing – on a fundamental level, quality calibration hasn’t been solved.
Answers to “What is good?” are relative by nature, mostly shaped by relationships between users and products.
I see the need to intensify collaboration and alignment between AI/ML developers and testers to make better AI. Whatever “better” means for you or for the users of the product.
What could you do now? Talk to fellow engineers, share your experience, ask questions.